Automatischer Videoschnitt durch Gesichtserkennung
11.02.2017

Kann ein Computer das Video einer Nachrichtensendung automatisiert schneiden, so dass der Nachrichtensprecher und die Berichte getrennt sind? Die Antwort lautet: ja. In folgendem Artikel zeige ich am Beispiel der Nachrichtensendung heute+ mit der Moderatorin Eva-Maria Lemke wie ein Video durch Gesichtserkennung und Stimmerkennung ohne menschlichen Eingriff automatisch geschnitten werden kann.
Wer sich nicht mit der grauen Theorie beschäftigen möchte, findet hier automatisch erzeugte Listen für den Videoschnitt der Nachrichtensendung Heute+.
Mustererkennung
Ich bin kein Freund des Begriffs "künstliche Intelligenz", da Computer nicht intelligent oder kreativ sind. Daher bevorzuge ich eher den Begriff "Mustererkennung". Für klar umrissene Aufgaben wie Gesichtserkennung und Stimmerkennung funktioniert Mustererkennung bereits ganz gut. Für den Videoschnitt habe ich mir die kostenlosen und quelloffenen Programme Openface zur Gesichtserkennung und Voice ID zur Stimmerkennung näher angesehen und unter dem Betriebssystem Linux Mint 18 ausprobiert.
Warum funktioniert die Mustererkennung für Nachrichtensendungen ?
Nachrichtensendungen eignen sich gut zur Mustererkennung, da:
- die Nachrichtensprecherin meistens direkt in die Kamera sieht, so dass die Gesichtserkennung funktioniert
- meist keine störenden Hintergrundgeräusche während der Moderation vorhanden sind, so dass die Stimmerkennung funktioniert
Bei Spielfilmen sind zum Beispiel die Gesichter nicht immer gut zu erkennen und die Stimmen durch Hintergrundgeräusche überlagert.
Welche Probleme gibt es?
Ein Problem fängt bereits beim Namen des Projekts "Openface" an. Openface gibt es zweimal. Einmal Openface zur Mimik-Erkennung und zweitens Openface zur Gesichtserkennung. Openface zur Mimik-Erkennung kann mehrere Personen auf einem Bild erkennen und kann sogar die Blickrichtung und Kopfhaltung einschätzen.

automatische Mimik-Erkennung durch OpenFace
Openface zur Gesichtserkennung basiert auf Openface zur Mimik-Erkennung - allerdings funktioniert die Erkennung von mehreren Gesichtern in einem Bild bei Openface zur Gesichtserkennung leider nicht oder zumindest nicht zuverlässig. Außerdem funktionieren beide Openface-Varianten nicht oder nicht gut, wenn ein Gesicht zur Seite gedreht ist. Openface wurde für einen anderen Zweck entwickelt. In dem folgenden Bild führt Eva-Maria Lemke ein Interview mit Anne Gellinek. Openface würde hierbei nur Anne Gellinek zuverlässig erkennen.
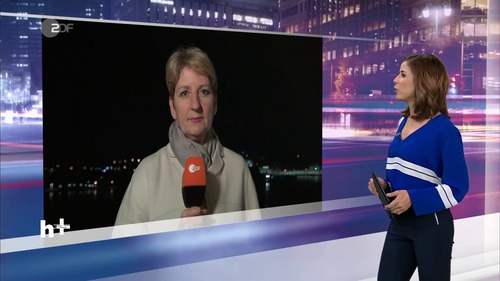
Eva-Maria Lemke im Gespräch mit Anne Gellinek
Außerdem gibt es in manchen Sendungen Abschnitte, in denen die Nachrichtensprecherin spricht, aber andere Bilder ins Video eingeblendet werden und somit das Gesicht nicht sichtbar ist. Die Gesichtserkennung allein reicht also zum Videoschnitt nicht aus. Deshalb muss zusätzlich die Stimmerkennung helfen. Das Erkennen von verschiedenen Sprechern mit Voice ID funktioniert erstaunlich gut. Leider gibt es bei Voice ID das Problem, dass das Training auf einen bestimmten Sprecher beziehungsweise eine bestimmte Sprecherin zumindest nach meinen kurzen Tests nicht zuverlässig funktioniert hat. Das Problem löse ich dadurch, dass ich die Stellen mit erfolgreicher Gesichtserkennung und der Stimmerkennung kombiniere. Schließlich gibt es noch das Problem des "ramp talk", bei der Musik oder ein Bericht bereits beginnt während die Nachrichtensprecherin noch spricht. Bei diesen "ramp talks" läßt sich die Stimme schlecht erkennen. Hier hilft wieder nur die Kombination aus Gesichtserkennung und Stimmerkennung.
Beispiel für die Erkennung
Das folgende Bild zeigt die Mustererkennung des Heuteplus-Videos vom 02. Februar 2017 im zeitlichen Verlauf. Zum Vergrößern einfach aufs Bild klicken. Die x-Achse ist die Zeit in Sekunden. In der obersten Zeile stehen die Minuten. In der zweiten Zeile werden ähnliche Stimmen von Sprechern durch dieselbe Farbe im Zeitverlauf dargestellt. In der dritten Zeile werden die Zeiten grün dargestellt, in denen das Gesicht der Nachrichtensprecherin mit einer gewissen Wahrscheinlichkeit erkannt wurde (aktuell mit 85% Wahrscheinlichkeit). In der 4. Zeile stellt die dunkelgrüne Farbe die Kombination aus Gesichtserkennung und Stimmerkennung dar (Addition der Zeiten der rosa und hellgrünen Balken). Diese Zeiten stimmen relativ gut mit der manuellen Prüfung überein (blau dargestellt).
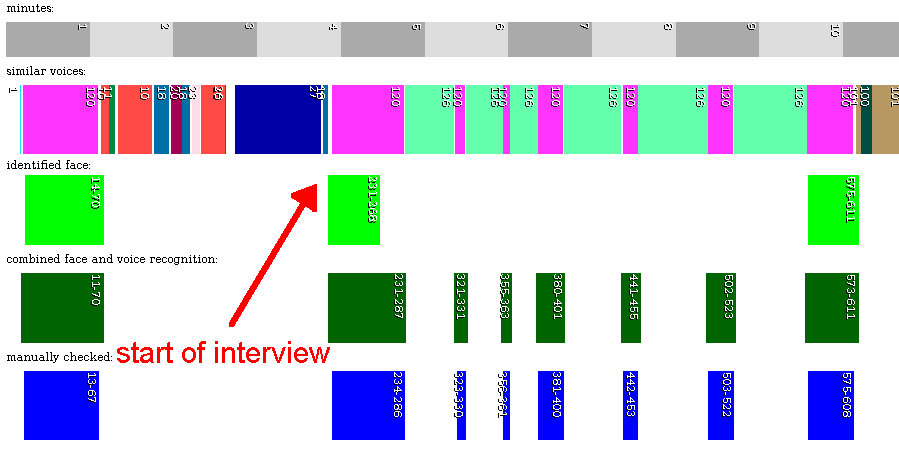
Stimmerkennung und Gesichtserkennung kombiniert (zum Vergrößern klicken)
Die Zeiten, in denen das Gesicht erkannt wurde (grün), stimmen mit den Zeiten der "rosa" Stimme mit Nummer 120 überein. Daraus kann man schlussfolgern, dass die "rosa" Stimme der Nachrichtensprecherin gehört. Allerdings zeigt die Stimmerkennung der "rosa" Stimme mehr Zeiten an, als die Gesichtserkennung. Nur die Kombination aus beiden Zeiten (dunkelgrün) stimmt mit der manuellen Prüfung der Zeiten (blau) überein. Außerdem läßt sich aus der Stimmenerkennung in der zweiten Zeile sehen, dass die Nachrichtensprecherin hier ein Interview geführt hat. Die "hellgrüne" Stimme und die "rosa" Stimme wechseln sich ab. Da die Nachrichtensprecherin beim Interview ihr Gesicht zur Seite gedreht hat, gibt es zu diesen Zeitpunkten keine erfolgreiche Gesichtserkennung.
Technischer Ablauf der Erkennung
Wie läßt sich die Theorie praktisch umsetzen? Zunächst muss die Software Voice ID und dann der docker-Container von Openface installiert werden. Eine Anleitung für docker mit Openface findet sich hier (unten auf der Seite). Docker sollte so konfiguriert werden, dass es ohne root-Rechte als normaler Benutzer ausgeführt werden kann. Das ganze habe ich unter dem Betriebssystem Linux Mint 18 getestet. Das Compilieren (Übersetzen) der Software from scratch und das Compilieren aller Abhängigkeiten hat einige Stunden gedauert. Die folgenden einzelnen Schritte habe ich nur zur Erklärung aufgeschrieben. Wer die komfortable Ein-Klick-Lösung möchte, findet weiter unten unter der Überschrift Download die Kurz-Variante.
Stimmenerkennung mit Voice ID
Im ersten Schritt werden mit dem Programm Voice ID die verschiedenen SprecherInnen aus dem Video erkannt. Die Option "-k" behält die erkannten WAV-Dateien mit den Stimmen.
vid -i "$video" -k
# list wave files with speakers sorted by time
cd "$video_base_name_without_extenstion"
ls -1 */*wav | sed 's|^\([^/]*\)/.*_\(0[0-9]*\)\.\(0[0-9]*\)\.wav|\2 \3 \1|g' | sort
Gesichtserkennung mit Openface
Im zweiten Schritt wird mit Hilfe des Programms ffmpeg aus dem Nachrichten-Video jede Sekunde ein Bild erzeugt.
mkdir images
ffmpeg -i "$video" -vf fps=1 images/"$video"_%04d.png
Im dritten Schritt werden aus jedem zweiten Bild des Videos die Gesichter gefunden. Warum nur jedes zweite Bild? Damit es schneller geht.
mkdir -p /home/user/share/lemke
# move every second image of the video to the shared directory for docker
mv "$video"_{0000..9999..2}.png /home/user/share/lemke
# run openface in docker with a shared directory
docker run -v /home/user/share:/share/ -t -i bamos/openface /bin/bash
# find faces in the images
cd /root/openface
./util/align-dlib.py /share/lemke/ align outerEyesAndNose /share/aligned --size 96
Im vierten Schritt versucht Openface die Gesichter mittels einer vorher trainierter Datenbank zu erkennen. Die Gesichter wurden im dritten Schritt aus den Video-Bildern herausgeschnitten. Übersteigt die Wahrscheinlichkeit der Erkennung einen gewissen Schwellwert, dann können auch noch die Bilder eine Sekunde davor und eine Sekunde danach zur Erkennung benutzt werden.
docker run -v /home/user/share:/share/ -t -i bamos/openface /bin/bash
# identify the faces
cd /root/openface
./demos/classifier.py infer /share/pattern_lemke/classifier.pkl /share/aligned/"$image" > /share/recognized_${image_number}.txt 2>&1
Schnittliste erstellen
Im fünften Schritt wird eine Liste mit Zeiten der Videoschnitte anhand der Wahrscheinlichkeit der Gesichtserkennung pro Bild erstellt.
Im sechsten Schritt werden die "Schnittlisten" von Gesichtserkennung und Stimmerkennung durch ein Ruby-Skript kombiniert.
Videoschnitt mit ffmpeg
Im siebten und letzten Schritt wird anhand der Schnittliste das Video der Nachrichtensendung geschnitten. Dazu wird eine "Segments"-Datei mit Start- und Ende-Zeit in Sekunden erstellt und an das Programm "ffmpeg" übergeben. Die Videos von Heuteplus sind so codiert, dass alle 2 Sekunden ein sogenannter "key frame" - also ein komplettes Bild im Videostrom gespeichert ist. Deshalb sollte die Start-Zeit durch 2 teilbar sein.
if ((startPositionSeconds % 2)); then
let startPositionSeconds--
fi
echo "file '$video'" >> segments.txt
echo "inpoint $startPositionSeconds" >> segments.txt
echo "outpoint $endPositionSeconds" >> segments.txt
ffmpeg -y -f concat -i segments.txt -c copy "${video}_combined.mp4"
Download
Die oben beschriebenen einzelnen Schritte habe ich für mehr Komfort in kleinen Shell-Skripten und Ruby-Skripten zusammengefasst. Das Software-Paket gibt es hier:
wget https://www.torsten-traenkner.de/projects/videocutting/pattern_recognition_tools.tgz
# extract
tar xzvf pattern_recognition_tools.tgz
cd pattern_recognition_tools/
# test it with a video of heute+
wget http://download.zdf.de/mp4/zdf/17/02/170203_heuteplus_hep/1/170203_heuteplus_hep_3296k_p15v13.mp4 -O 2017-02-03_heuteplus.mp4
./automagicallyCutVideo.sh 2017-02-03_heuteplus.mp4
Performance
Ein Video heute+ mit 18 Minuten Länge dauert bis zur fertigen Erkennung einer Sendung etwa 70 Minuten - je nach benutzter Hardware.
Demo time
Die generierten Listen für den Videoschnitt von heute+ gibt es hier.
Ausblick
Es gibt einige Möglichkeiten zur Verbesserung der Software, die ich aber aufgrund mangelnder Zeit vermutlich nicht umsetzen werde:
- Software auf dem Raspberry Pi laufen lassen um Energie zu sparen
- Erkennung von mehreren Gesichtern verbessern
- entweder mit Openface zur Mimikerkennung oder
- durch Ausschneiden des rechten Drittels des Bildes, wo die Nachrichtensprecherin gelegentlich steht
width=$(identify "$filename" | sed 's|.*PNG \([^x]*\).*|\1|g')
height=$(identify "$filename" | sed 's|.*PNG [0-9]*x\([^ ]*\) .*|\1|g')
let third=3*width/10
let offset=width-third
convert "$filename" -crop ${third}x${height}+${offset}+0 right_third.png
- als zusätzliches Merkmal die Position und Kopfhaltung der Nachrichtensprecherin zur Erkennung der Szenen benutzen
- eventuell muss das neuronale Netz zur Gesichtserkennung zu einem späteren Zeitpunkt bei Veränderung des Gesichts neu trainiert werden
Note for English speakers
This article is about automated video editing / cutting / trimming of a news show by using pattern recognition. In a news show you usually see the face of the presenter, which can be identified with the open source project Openface and voice recognition of the presenter can be done with Voice ID. With this "articifal intelligence" you can separate video snippets of the presenter and the news. Since I'm too busy to write in English, feel free to translate this article. Please add a link to this original article. Be aware that I cannot give support for the software.
Einige Hinweise zum Schluß
Im Augenblick (2017) habe ich leider nicht viel Zeit, um auf Feedback zu reagieren oder Support für die schnell zusammengehackte Software zu geben. Außerdem versteht sich für Hobby-Software wie immer: keine Gewährleistung auf irgendwas.
Weiterführende Links: automatisch erzeugte Listen für den Videoschnitt der Nachrichtensendung Heute+.